Overview

Learn not one, but many, ways to succeed in an environment - while still using shared weights.
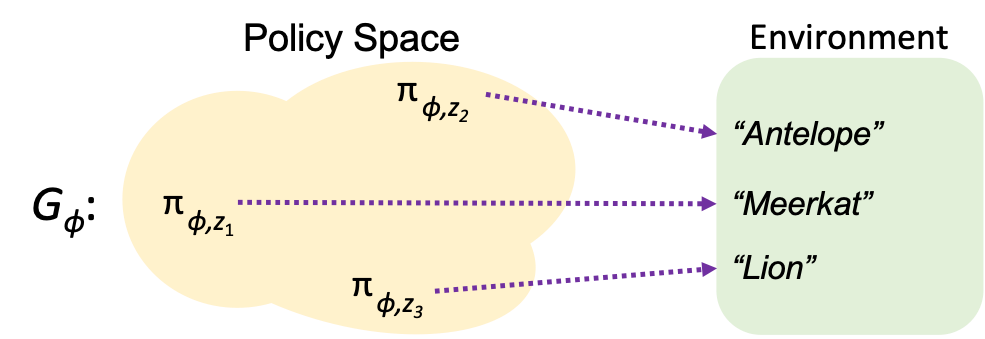

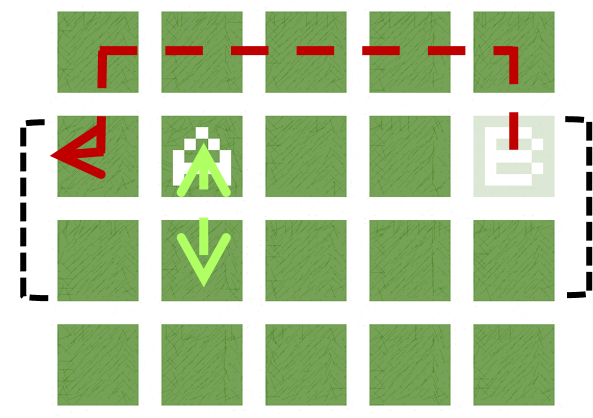
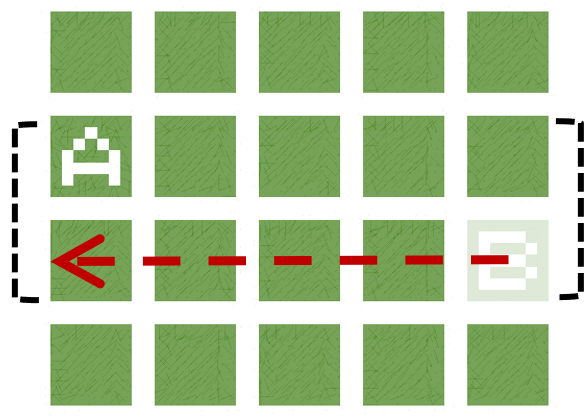
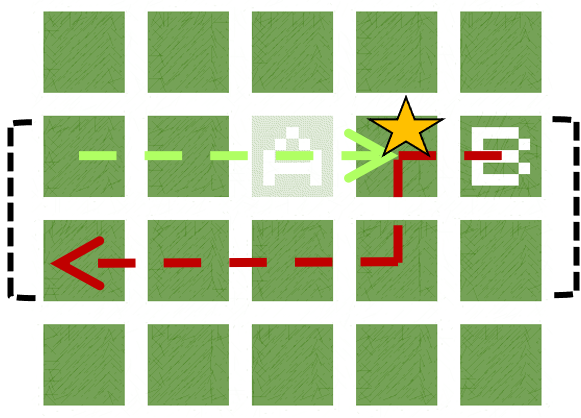
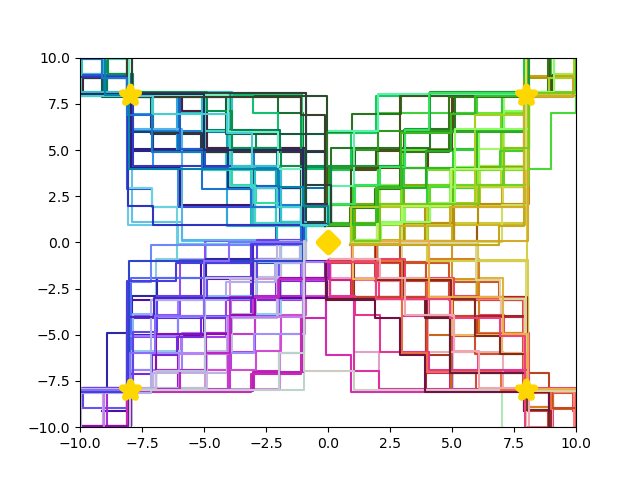
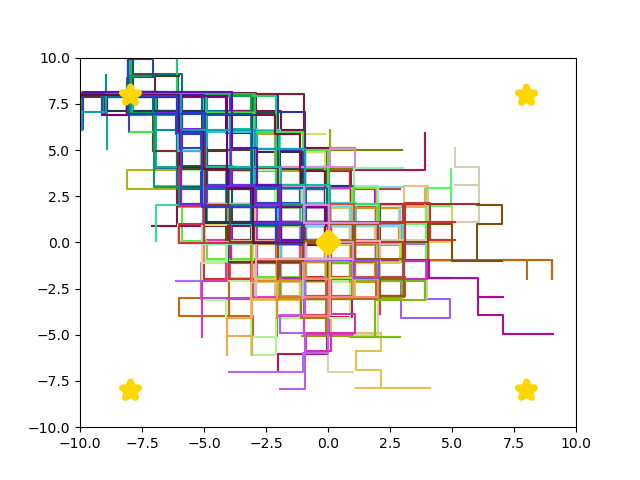
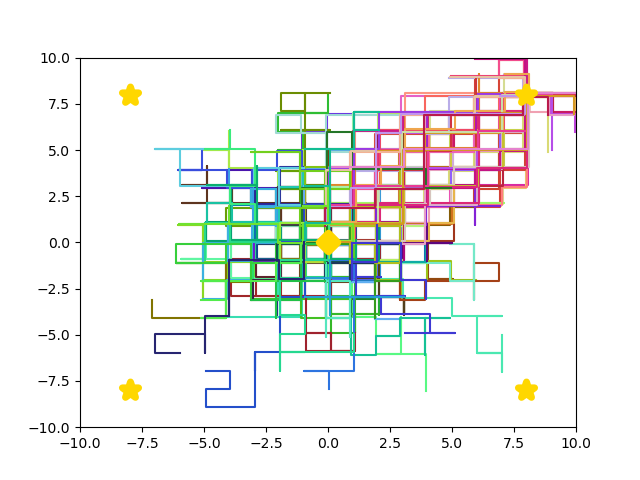
By learning a diverse policy space in an open-ended environment with many solutions, we show that we can adapt to future ablations simply by selecting one of our many learned "species" - without changing parameter weights.


We also learn a policy space in a competitive, two-player, zero-sum game. Here, no single deterministic policy is optimal against all adversaries. On the other hand, our ADAP policy space can be naturally adaptable to a wide array of both challenging and naive adversaries.
Overall, we hope to show how it can be beneficial in RL settings to optimize not just for reward, but also for diversity of behavior. As environments continue to increase in complexity and open-endedness -- filled with branching paths to success -- it makes sense to learn not just one, but many, solutions.









 (reduced video quality for memory compression)
(reduced video quality for memory compression)